学习爬虫的路线
- Selenium
- pymysql
- scrapy
Selenium
通过代码控制浏览器这里以Chrome
# 使用 Service 对象初始化驱动
service = Service()
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
driver = webdriver.Chrome(service=service, options=chrome_options)
# 打开网页
driver.get("https://www.bilibili.com/")
# 点击class = channel-link的标签
driver.find_element(By.CLASS_NAME, "channel-link").click()
# 根据class获取标签,示例-搜索框
search_element = driver.find_element(By.CLASS_NAME, "nav-search-input")
search_element.send_keys("你好")
search_element.send_keys(Keys.RETURN)
# 根据超链接标题点击
driver.find_element(By.LINK_TEXT, "音乐").click()
# 悬停-点击悬停后显示的子类
element = driver.find_element(By.LINK_TEXT, "音乐")
ActionChains(driver).move_to_element(element).perform()
time.sleep(1)
# 点击子类
c_element = driver.find_element(By.LINK_TEXT, "原创音乐")
c_element.click()
#截图
driver.save_screenshot("jietu.jpg")
pymysql
这里就不过多介绍,官网有使用说明。有需要可以自己封装一下
import pymysql
connection = pymysql.connect(host = '127.0.0.1',
user = 'root',
password= 'password',
db = 'db',
charset= 'utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
#插入
# sql = "INSERT INTO `medicine` VALUES(%s, %s)"
# cursor.execute(sql, (100, 'ni'))
# connection.commit()
#查询
sql = "SELECT * FROM medicine"
cursor.execute(sql)
res = cursor.fetchall()
print(res)
finally:
connection.close()
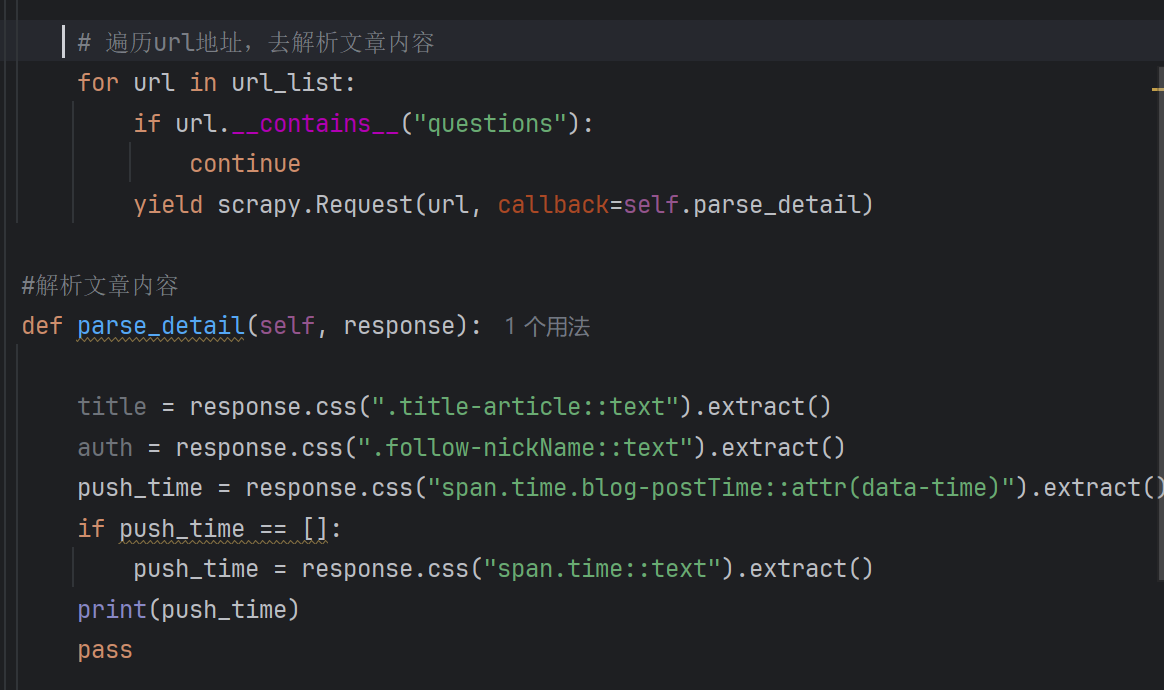
scrapy
1 下载Scrapy
pip install scrapy
2 在虚拟环境下创建Scrapy项目
scrapy startproject fileName
创建爬虫后:
可以根据提示

生成一个对应的类
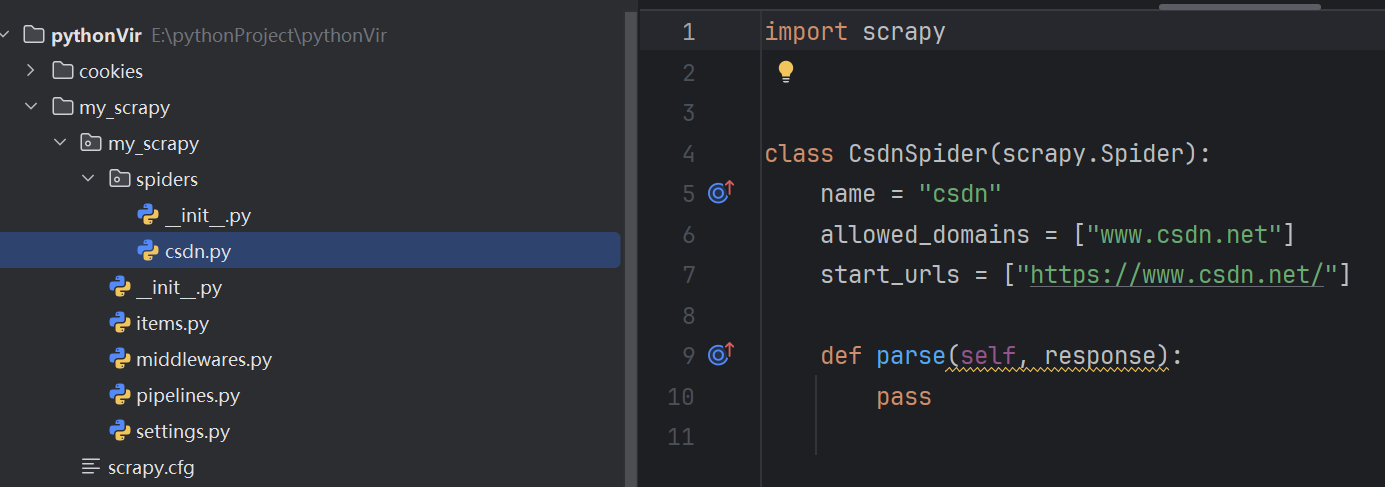
项目结构:
scrapy.cfg:项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息
items.py:格式化数据
pipelines.py:数据处理行为,如:一般结构化的数据持久化
settings.py:配置文件
spider:爬虫目录
3 编写执行代码
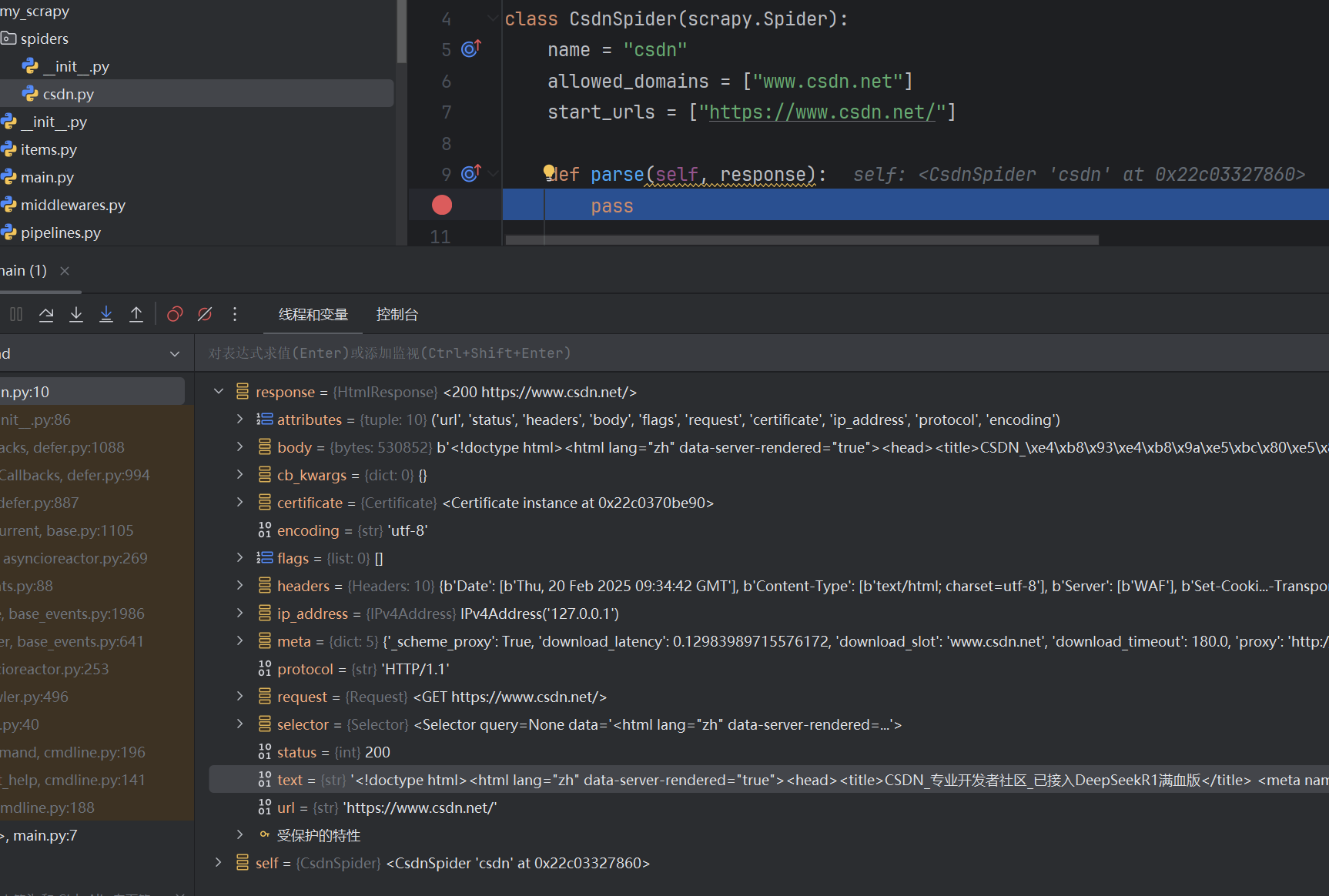
执行代码:

断点查看
4 根据response的数据进行提取